
1. Intro
LeNet is a very first deep learning model that introduced in the research paper “Gradient-Based Learning Applied To Document Recognition” in the year 1998 by four legendary researchers, Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick Haffner. Many of the listed authors of the paper have gone on to provide several significant academic contributions to the field of deep learning.

From left: Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick Haffner
This article will introduce the LeNet-5 CNN architecture as described in the original paper, along with the implementation of the architecture using TensorFlow 2.0. Then conclude with the utilization of the implemented LeNet-5 CNN for the classification of images from the MNIST dataset.
![]()
What to find in this article:
- Understanding of components within a convolutional neural network
- Key definitions of terms commonly used in deep learning and machine learning
- Understanding of LeNet-5 architecture as presented in the original research paper
- Implementation of a neural network using TensorFlow and Keras
The content in this article is written for Deep learning and Machine Learning students of all levels. For those who are eager to get coding, scroll down to the Implementation section.
2. Convolutional Neural Networks
Convolutional Neural Networks are a standard form of neural network architecture for solving tasks associated with images. Solutions for tasks such as object detection, face detection, pose estimation and more, usually have CNN architecture variants.
A few characteristics of the CNN architecture makes them more favourable in several computer vision tasks. It would be good if we could introduce each characteristics before we get started on working with the LeNet-5 architecture.
Some convolutional networks characteristics that we are interested in here:
- Local respective fields
- Sub-sampling
- Weight sharing
LeNet-5 CNN architecture is made up of 7 layers. The layer composition consists of 3 convolutional layers, 2 subsampling layers and 2 fully connected layers.
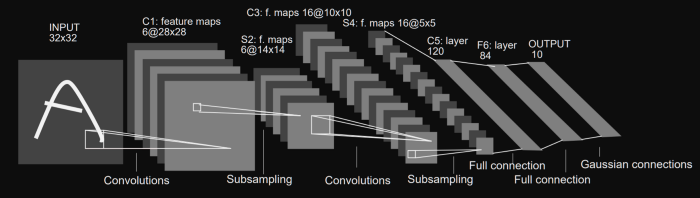
LeNet architecture
The diagram above shows a depiction of the LeNet-5 architecture, as illustrated in the original paper.
The first layer is the input layer — this is generally not considered a layer of the network as nothing is learnt in this layer. The input layer is built to take in 32x32, and these are the dimensions of images that are passed into the next layer. Those who are familiar with the MNIST dataset will be aware that the MNIST dataset images have the dimensions 28x28. To get the MNIST images dimension to the meet the requirements of the input layer, the 28x28 images are padded.
The grayscale images used in the research paper had their pixel values normalized from 0 to 255, to values between -0.1 and 1.175. The reason for normalization is to ensure that the batch of images have a mean of 0 and a standard deviation of 1, the benefits of this is seen in the reduction in the amount of training time. In the image classification with LeNet-5 example below, we’ll be normalizing the pixel values of the images to take on values between 0 to 1.
The LeNet-5 architecture utilizes two significant types of layer construct: convolutional layers and subsampling layers.
- Convolution layers
- Sub-sampling layers
Within the research paper and the image below, convolutional layers are identified with the ‘Cx’, and subsampling layers are identified with ‘Sx’, where ‘x’ is the sequential position of the layer within the architecture. ‘Fx’ is used to identify fully connected layers. This method of layer identification can be seen in the image above.
The official first layer convolutional layer C1 produces as output 6 feature maps, and has a kernel size of 5x5. The kernel/filter is the name given to the window that contains the weight values that are utilized during the convolution of the weight values with the input values. 5x5 is also indicative of the local receptive field size each unit or neuron within a convolutional layer. The dimensions of the six feature maps the first convolution layer produces are 28x28.
A subsampling layer ‘S2’ follows the ‘C1’ layer’. The ‘S2’ layer halves the dimension of the feature maps it receives from the previous layer; this is known commonly as downsampling.
The ‘S2’ layer also produces 6 feature maps, each one corresponding to the feature maps passed as input from the previous layer. This link contains more information on subsampling layers.
More information on the rest of the LeNet-5 layers is covered in the implementation section. Below is a table that summarises the key features of each layer:
| Layer name | Input | Kernel size | Output | Activation |
|---|---|---|---|---|
| Input | 28x28x1 | None | 28x28x1 | Relu |
| Convolution 1 | 28x28x1 | 5x5 | 24x24x6 | Relu |
| Max pooling 1 | 24x24x6 | 2x2 | 12x12x6 | Relu |
| Convolution 2 | 12x12x6 | 5x5 | 8x8x16 | Relu |
| Max pooling 2 | 8x8x16 | 1x1 | 4x4x16 | Relu |
| Flatten | 4x4x16 | None | 256x1 | None |
| Dense 1 | 256x1 | None | 120x1 | Relu |
| Dense 2 | 120x1 | None | 84x1 | Relu |
| Dense 3 | 84x1 | None | 10x1 | Softmax |
We begin implementation by importing the libraries we will be utilizing:
- TensorFlow: An open-source platform for the implementation, training, and deployment of machine learning models.
- Keras: An open-source library used for the implementation of neural network architectures that run on both CPUs and GPUs.
- Numpy: A library for numerical computation with n-dimensional arrays.
import sys
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, losses, optimizers
from tensorflow.keras.datasets import mnist
from matplotlib import pyplot as plt
Next, we load the MNIST dataset using the Keras library. The Keras library has a suite of datasets readily available for use with easy accessibility.
We are also required to partition the dataset into testing, validation and training. Here are some quick descriptions of each partition category.
- Training Dataset: This is the group of our dataset used to train the neural network directly. Training data refers to the dataset partition exposed to the neural network during training.
- Validation Dataset: This group of the dataset is utilized during training to assess the performance of the network at various iterations.
- Test Dataset: This partition of the dataset evaluates the performance of our network after the completion of the training phase.
It is also required that the pixel intensity of the images within the dataset are normalized from the value range 0–255 to 0–1.
(xTrain, yTrain), (xTest, yTest) = mnist.load_data()
plt.figure(figsize=(10,10))
indexes = np.random.randint(0, len(xTrain), 9)
for i in range(len(indexes)):
plt.subplot(3,3,i+1)
plt.imshow(xTrain[indexes[i]])
plt.title(yTrain[indexes[i]])
plt.show()
In the code snippet above, we expand the dimensions of the training and dataset. The reason we do this is that during the training and evaluation phases, the network expects the images to be presented within batches; the extra dimension is representative of the numbers of images in a batch.
The code below is the main part where we implement the actual LeNet-5 based neural network. Keras provides tools required to implement the classification model. Keras presents a Sequential API for stacking layers of the neural network on top of each other.
numClasses = 10
inputs = layers.Input((28,28,1))
x = layers.Conv2D(6, 5, activation="relu")(inputs)
x = layers.MaxPool2D()(x)
x = layers.Conv2D(16, 5, activation="relu")(x)
x = layers.MaxPool2D()(x)
x = layers.Flatten()(x)
x = layers.Dense(120, activation="relu")(x)
x = layers.Dense(84, activation="relu")(x)
outputs = layers.Dense(numClasses)(x)
leNet5 = keras.Model(inputs=inputs, outputs=outputs)
leNet5.compile(
loss = losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer = optimizers.Adam(),
metrics = ["accuracy"]
)
leNet5.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 24, 24, 6) 156
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 12, 12, 6) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 8, 8, 16) 2416
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 4, 4, 16) 0
_________________________________________________________________
flatten (Flatten) (None, 256) 0
_________________________________________________________________
dense (Dense) (None, 120) 30840
_________________________________________________________________
dense_1 (Dense) (None, 84) 10164
_________________________________________________________________
dense_2 (Dense) (None, 10) 850
=================================================================
Total params: 44,426
Trainable params: 44,426
Non-trainable params: 0
We first assign the variable lenet_5_model to an instance of the tf.keras.Sequential class constructor. Within the class constructor, we then proceed to define the layers within our model.
The C1 layer is defined by the linekeras.layers.Conv2D(6, kernel_size=5, strides=1, activation='tanh', input_shape=train_x[0].shape, padding='same'). We are using the tf.keras.layers.Conv2D class to construct the convolutional layers within the network. We pass a couple of arguments which are described here.
- Activation Function: A mathematical operation that transforms the result or signals of neurons into a normalized output. An activation function is a component of a neural network that introduces non-linearity within the network. The inclusion of the activation function enables the neural network to have greater representational power and solve complex functions.
The rest of the convolutional layers follow the same layer definition as C1 with some different values entered for the arguments.
In the original paper where the LeNet-5 architecture was introduced, subsampling layers were utilized. Within the subsampling layer the average of the pixel values that fall within the 2x2 pooling window was taken, after that, the value is multiplied with a coefficient value. A bias is added to the final result, and all this is done before the values are passed through the activation function.
But in our implemented LeNet-5 neural network, we’re utilizing the tf.keras.layers.AveragePooling2D constructor. We don’ t pass any arguments into the constructor as some default values for the required arguments are initialized when the constructor is called. Remember that the pooling layer role within the network is to downsample the feature maps as they move through the network.
There are two more types of layers within the network, the flatten layer and the dense layers.
The flatten layer is created with the class constructor tf.keras.layers.Flatten.
The purpose of this layer is to transform its input to a 1-dimensional array that can be fed into the subsequent dense layers.
The dense layers have a specified number of units or neurons within each layer, F6 has 84, while the output layer has ten units.
The last dense layer has ten units that correspond to the number of classes that are within the MNIST dataset. The activation function for the output layer is a softmax activation function.
- Softmax: An activation function that is utilized to derive the probability distribution of a set of numbers within an input vector. The output of a softmax activation function is a vector in which its set of values represents the probability of an occurrence of a class/event. The values within the vector all add up to 1.
Keras provides the ‘compile’ method through the model object we have instantiated earlier. The compile function enables the actual building of the model we have implemented behind the scene with some additional characteristics such as the loss function, optimizer, and metrics.
To train the network, we utilize a loss function that calculates the difference between the predicted values provided by the network and actual values of the training data.
The loss values accompanied by an optimization algorithm(Adam) facilitates the number of changes made to the weights within the network. Supporting factors such as momentum and learning rate schedule, provide the ideal environment to enable the network training to converge, herby getting the loss values as close to zero as possible.
During training, we’ll also validate our model after every epoch with the valuation dataset partition created earlier
history = leNet5.fit(xTrain, yTrain, validation_data=(xTest,yTest), batch_size=64, epochs=10)
Epoch 1/10
938/938 [==============================] - 10s 10ms/step - loss: 1.1559 - accuracy: 0.7988 - val_loss: 0.1056 - val_accuracy: 0.9681
Epoch 2/10
938/938 [==============================] - 9s 10ms/step - loss: 0.0982 - accuracy: 0.9690 - val_loss: 0.0759 - val_accuracy: 0.9763
Epoch 3/10
938/938 [==============================] - 9s 10ms/step - loss: 0.0595 - accuracy: 0.9809 - val_loss: 0.0706 - val_accuracy: 0.9792
Epoch 4/10
938/938 [==============================] - 9s 10ms/step - loss: 0.0545 - accuracy: 0.9836 - val_loss: 0.0723 - val_accuracy: 0.9770
Epoch 5/10
938/938 [==============================] - 9s 10ms/step - loss: 0.0472 - accuracy: 0.9856 - val_loss: 0.0594 - val_accuracy: 0.9825
Epoch 6/10
938/938 [==============================] - 9s 10ms/step - loss: 0.0364 - accuracy: 0.9877 - val_loss: 0.0532 - val_accuracy: 0.9850
Epoch 7/10
938/938 [==============================] - 9s 10ms/step - loss: 0.0358 - accuracy: 0.9887 - val_loss: 0.0813 - val_accuracy: 0.9776
Epoch 8/10
938/938 [==============================] - 10s 10ms/step - loss: 0.0333 - accuracy: 0.9895 - val_loss: 0.0682 - val_accuracy: 0.9829
Epoch 9/10
938/938 [==============================] - 9s 10ms/step - loss: 0.0271 - accuracy: 0.9916 - val_loss: 0.0618 - val_accuracy: 0.9839
Epoch 10/10
938/938 [==============================] - 9s 10ms/step - loss: 0.0265 - accuracy: 0.9913 - val_loss: 0.0729 - val_accuracy: 0.9835
313/313 [==============================] - 1s 3ms/step - loss: 0.0729 - accuracy: 0.9835
After training, you will notice that your model achieves a validation accuracy of over 90%. But for a more explicit verification of the performance of the model on an unseen dataset, we will evaluate the trained model on the test dataset partition created earlier.
leNet5.evaluate(xTest, yTest)
[0.07292196899652481, 0.9835000038146973]
After training my model, I was able to achieve 98% accuracy on the test dataset, which is quite useful for such a simple network.
Analyze the model training and performance
Confusion matrix
from sklearn.metrics import confusion_matrix, accuracy_score
yPred = leNet5.predict(xTest)
yPred = np.argmax(yPred, axis=-1)
conf = confusion_matrix(yTest, yPred, normalize=None)
accuracy = accuracy_score(yPred, yTest)
print("Accuracy Score:", accuracy)
plt.imshow(conf)
plt.title("Confusion matrix")
plt.show()
Accuracy and error plots
loss_train = history.history['loss']
loss_val = history.history['val_loss']
epochs = range(1,11)
plt.plot(epochs, loss_train, 'g', label='Training loss')
plt.plot(epochs, loss_val, 'b', label='validation loss')
plt.title('Training and Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
You can see the complete project code in my github repo from here.
I hope you found the article useful.
Comment Channel