
1. Intro
Big Data powered machine learning and deep learning has yielded impressive advances in many fields. One example is the release of ImageNet consisting of more than 15 million labelled high-resolution images of 22,000 categories which revolutionized the field of computer vision. State-of-the-art models have already achieved a 98% top-five accuracy on the ImageNet dataset, so it seems as though these models are foolproof and that nothing can go wrong.
However, recent advances in adversarial training have found that this is an illusion. A good model misbehaves frequently when faced with adversarial examples. The image below illustrates the problem:
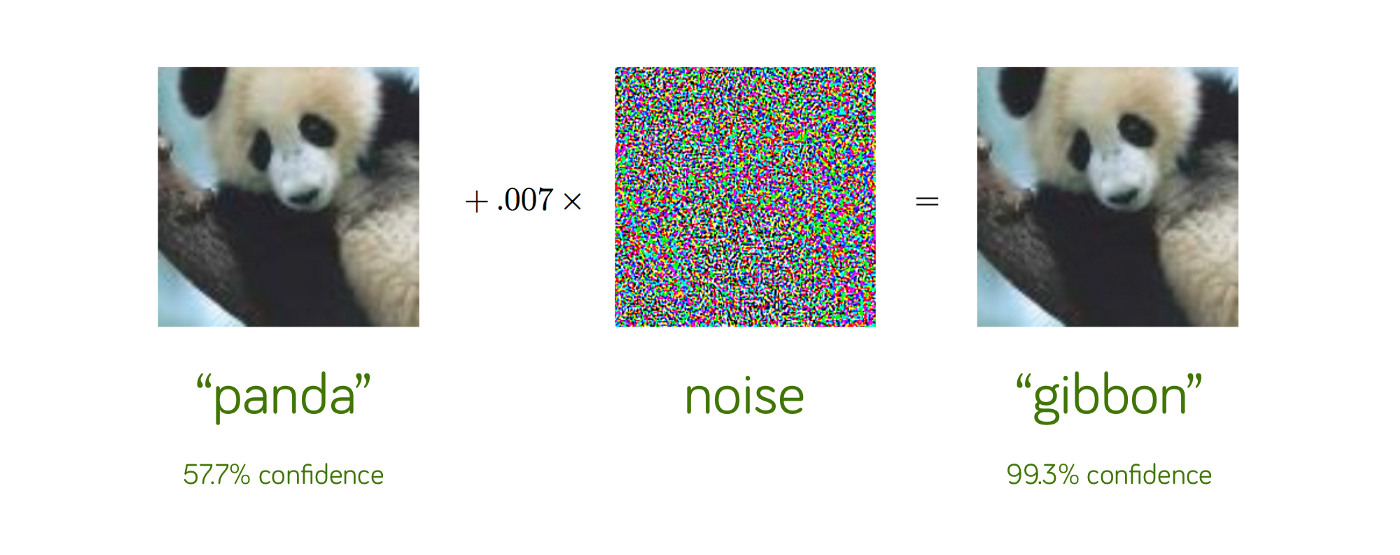
The model initially classifies the panda picture correctly, but when some noise, imperceptible to human beings, is injected into the picture, the resulting prediction of the model is changed to another animal, gibbon, even with such a high confidence. To us, it appears as if the initial and altered images are the same, although it is radically different to the model. This illustrates the threat these adversarial attacks pose — we may not perceive the difference so we cannot tell an adversarial attack as happened. Hence, although the output of the model may be altered, we cannot tell if the output is correct or incorrect.
This formed the motivation behind the talk for Professor Ling Liu’s keynote speech at the 2019 IEEE Big Data Conference, where she touched on types of adversarial attacks, how adversarial examples are generated, and how to combat against these attacks. Without further ado, I will get into the contents of her speech.
2. Types of adversarial attacks
Adversarial attacks are classified into two categories — targeted attacks and untargeted attacks.
The targeted attack has a target class, Y, that it wants the target model, M, to classify the image I of class X as. Hence, the goal of the targeted attack is to make M misclassify by predicting the adversarial example, I, as the intended target class Y instead of the true class X. On the other hand, the untargeted attack does not have a target class which it wants the model to classify the image as. Instead, the goal is simply to make the target model misclassify by predicting the adversarial example, I, as a class, other than the original class, X. Researchers have found that in general, although untargeted attacks are not as good as targeted attacks, they take much less time. Targeted attacks, although more successful in altering the predictions of the model, come at a cost (time).
3. How are Adversarial Examples Generated
Having understood the difference between targeted and untargeted attacks, we now come to the question of how these adversarial attacks are carried out. In a benign machine learning system, the training process seeks to minimize the loss between the target label and the predicted label, formulated mathematically as such:
During the testing phase, the learned model is tested to determine how well it can predict the predicted label. Error is then calculated by the sum of the loss between the target label and the predicted label, formulated mathematically as such: In adversarial attacks, the following 2 steps are taken:
- The query input is changed from the benign input x to \(x^\prime\).
- An attack goal is set such that the prediction outcome, \(H(x)\) is no longer \(y\). The loss is changed from \(L(H(x_i), y_i)\) to \(L(H(x_i), y^{\prime}_i)\) where \(y^{\prime}_i \ne y_i\).
4. Adversarial Perturbation
One way the query input is changed from x to x’ is through the method called “adversarial perturbation”, where the perturbation is computed such that the prediction will not be the same as the original label. For images, this can come in the form of pixel noise as we saw above with the panda example. Untargeted attacks have the single goal of maximizing the loss between H(x) and H(x’) until the prediction outcome is not y (the real label). Targeted attacks have an additional goal of not only maximizing the loss between H(x) and H(x’) but also to minimize the loss between H(x’) and y’ until H(x’) = y’ instead of y.
Adversarial perturbation can then be categorized into one-step and multi-step perturbation. As the names imply, the one-step perturbation only involves a single stage — add noise once and that is it. On the other hand, the multi-step perturbation is an iterative attack that makes small modifications to the input each time. Therefore, the one-step attack is fast but excessive noise may be added, hence making it easier for humans to detect the changes. Furthermore, it places more weight on the objective of maximizing loss between H(x) and H(x’) and less on minimizing the amount of perturbation. Conversely, the multi-step attack is more strategic as it introduces small amounts of perturbation at each time. However, this also means such an attack is computationally more expensive.
5. Black Box VS White Box Attacks
Now that we have looked at how adversarial attacks are generated, some astute readers may realize one fundamental assumption these attacks take on — that the attack target prediction model, H, is known to the adversary. Only when the targeted model is known can it be compromised to generate adversarial examples by changing the input. However, attackers do not always know or have access to the targeted model. This may sound like a surefire way to ward off these adversarial attackers, but the truth is that black box attacks are also highly effective. Black box attacks are based on the notion of transferability of adversarial examples — the phenomenon whereby adversarial examples, although generated to attack a surrogate model G, can achieve impressive results when attacking another model H. The steps taken are as follows:
- The attack target prediction model H is privately trained and unknown to the adversary.
- A surrogate model G, which mimics H, is used to generate adversarial examples.
- By using the transferability of adversarial examples, black box attacks can be launched to attack H.
This attack can be launched either with the training dataset being known or unknown. In the case where the dataset is known to the adversary, the model G can be trained on the same dataset as model H to mimic H.
When the training dataset is unknown however, adversaries can leverage on Membership Inference Attacks, whereby an attack model whose purpose is to distinguish the target model’s behavior on the training inputs from its behavior on the inputs that it did not encounter during training is trained. In essence, this turns into a classification problem to recognize differences in the target model’s predictions on the inputs that it trained on versus the inputs that it did not train on. This enables the adversary to obtain a better sense of the training dataset D which model H was trained on, enabling the attacker to generate a shadow dataset S on the basis of the true training dataset so as to train the surrogate model G. Having trained G on S where G mimics H and S mimics D, black box attacks can then be launched on H.
5.1 Black Box Attacks
Now that we have seen how black box attacks vary from white box attacks in that the target model H is unknown to the adversary, we will cover the various tactics used in black box attacks.
5.2 White Box Attacks
5.3 Physical Attacks
One simple way in which the query input is changed from x to x’ is by simply adding something physically (eg. bright colour) to disturb the model. One example is how researchers at CMU added eyeglasses to a person in an attack against facial recognition models. The image below illustrates the attack:
The first row of images correspond to the original image modified by adding the eyeglasses, and the second row of images correspond to the impersonation targets, which are the intended misclassification targets. Just by adding the eyeglasses onto the original image, the facial recognition model was tricked into classifying the images on the top row as the images in the bottom row.
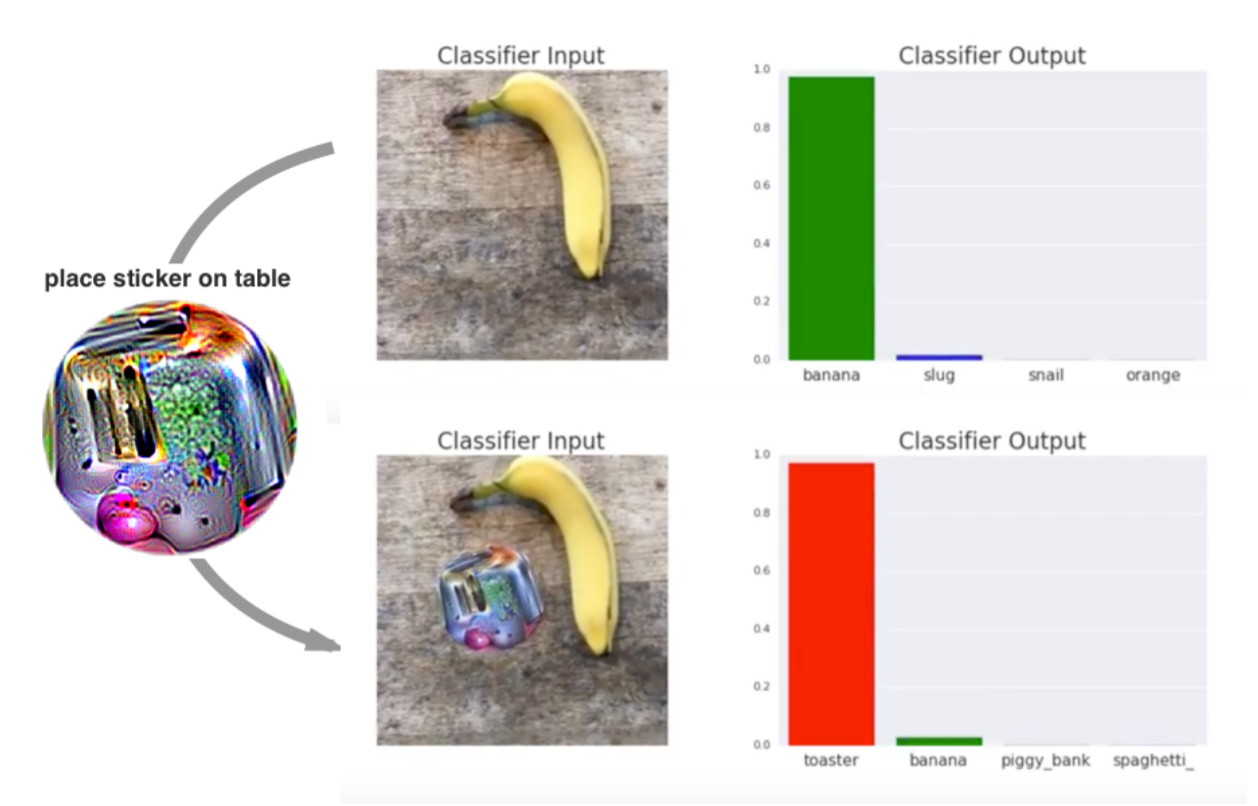
Another example comes from researchers at Google who added stickers to the input image to change the classification of the image, as illustrated by the image below:

These examples show how effective such physical attacks can be.
5.4 Out of Distribution (OOD) Attack
Another way in which black box attacks are carried out is through out-of-distribution (OOD) attacks. The traditional assumption in machine learning is that all train and test examples are drawn independently from the same distribution. In an OOD attack, this assumption is exploited by providing images of a different distribution from the training dataset to the model, for example feeding TinyImageNet data into a CIFAR-10 classifier which would lead to an incorrect prediction with high confidence.
6. How Can We Trust Machine Learning?
Now that we have taken a look at the various types of adversarial attacks, a natural question then comes — how can we trust our machine learning models if they are so susceptible to adversarial attacks?
One possible approach has been proposed by Chow et al. in 2019 in the paper titled “Denoising and Verification Cross-Layer Ensemble Against Black-box Adversarial Attacks”. The approach is centred around enabling machine learning systems to automatically detect adversarial attacks and then automatically repair them through the use of denoising and verification ensembles.
7. Denoising Ensembles
First, input images have to pass through denoising ensembles that attempt different methods to remove any added noise to the image, for example adding Gaussian noise. Since the specific noise added to the image by the adversary is unknown to the defender, there is a need for an ensemble of denoisers to each attempt to remove each type of noise.
The image below shows the training process for the denoising autoencoder — the original image is injected with some noise that the attacker might inject, and the autoencoder tries to reconstruct the original uncorrupted image. In the training process, the objective is to reduce the reconstruction error between the reconstructed image and the original image.
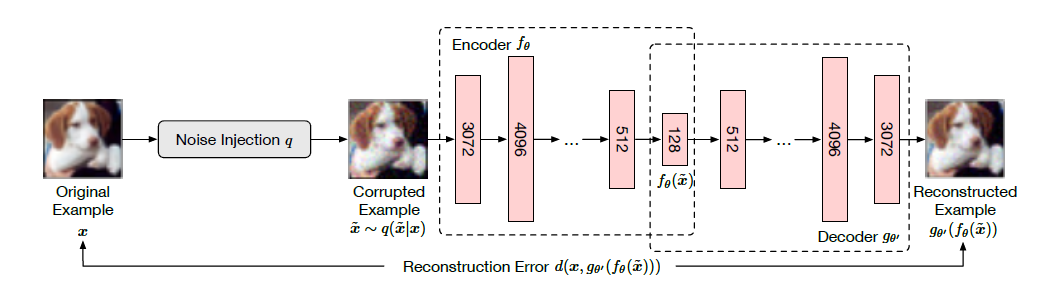
By developing an ensemble of these autoencoders each trained to remove a specific type of noise, the hope is that the corrupted images would be sufficiently denoised such that it is close to the original uncorrupted image to allow for image classification.
7.1 Verification Ensemble
After the images have been denoised, they then go through a verification ensemble which reviews every denoised image produced by each denoiser and then classifies the denoised image. Each classifier in the verification ensemble classifies each denoised image, and the ensemble then votes to determine the final category the image belongs to. This means that although some images may not have been denoised the correct way in the denoising step, the verification ensemble votes on all the denoised images, thereby increasing the likelihood of making a more accurate prediction.
7.2 Diversity
Diversity of the denoisers and verifiers have found to be very important because firstly, adversarial attackers will get better at altering images so there is a need for a diverse group of denoisers that can handle a variety of corrupted images. Following this, there is also a need for verifiers to be diverse so they can generate a variety of classifications so that it would be difficult adversarial attackers to manipulate them just as how they have managed to manipulate normal classifiers that we trust and use so frequently in machine learning.
This remains an open problem because, after all these decisions by the various verifiers, there is still a final decision maker that needs to decide whose opinion to listen to. The final decision maker would need to preserve the diversity present in the ensemble, which is not an easy task to tackle.
8. Conclusion
We have taken a look at various types of adversarial attacks as well as a promising method to defend against these attacks. This is definitely something to keep in mind when we implement machine learning models. Instead of blindly trusting the models to produce the correct results, we need to guard against these adversarial attacks and always think twice before we accept the decisions made by these models.
A huge thanks to Professor Liu for this enlightening keynote on this pressing problem in machine learning!
Comment Channel